Motivation and goals
DICOM is the standard image format and protocol when working with medical images in the clinic. Python has support for reading and writing DICOM images through the use of python packages, e.g. pydicom or GDCM. These packages, however, leave the reading and sorting of multiple files to the user. Also, they do not easily provide access to medical images stored in other formats: NIfTI and ITK to name a few.
When setting up pipelines to process clinical data, patient information should be maintained throughout to maintain patient safety. If the process involves DICOM data only, this requirement is easily fulfilled. However, some popular image processing systems require formats that do not maintain patient information. The ability to attach DICOM header data to these other formats let the user exploit a wider set of image processing software.
Imagedata extends NumPy arrays with DICOM information and functionality. Additionally, importing and exporting images to other image formats is available through a plugin architecture.
Imagedata as a Python package provides functions which supports developing Python applications, including reading and writing complete image series, and displaying image series using a simple viewer.
Design
The imagedata.Series class is subclassed from numpy.ndarray,
and as such inherits the methods of ndarray.
Examples are the shape and dtype attributes.
In addition, Series objects add selected attributes, like
spacing, sliceLocations, patientName, studyInstanceUID.
DICOM reading and writing depends on the pydicom and pynetdicom libraries.
The Series object can be instantiated from a NumPy array, from a DICOM source, or from some other image format source. The Series object maintains header data as close to the DICOM standard as possible, describing demographic data, study data and geometric data. When importing or exporting images to other formats, imagedata will convert header data when supported be these other formats. A DICOM source can be used as a template to construct a DICOM header for non-DICOM data. By using the existing Study Instance UID and constructing a new Series Instance UID, the new Series object can be imported into a DICOM server (PACS) as a new series in an existing study.
One particular property of Series is the axes property. Axes defines each dimension of the Series multi-dimensional array. This might be axes in the spatial domain, time domain, or some tag based domain. Example tag domains are the b-values of a diffusion weighted MRI acquisition. Slicing the Series array will also slice the axes property accordingly.
The import and export of data builds on three kind of plugins:
Format: The coding/decoding of an image format like DICOM, NIfTI, etc.
Archive: The packing of individual files. Most typically the files reside in a filesystem. The zip archive plugin supports packing files in a zip archive.
Transport: Plugins to access local files, or files on remote servers like a DICOM server.
The addressing of a source or destination follows a url specification, e.g.:
file:///local_directory : Access a directory on local filesystem
file:///zipfile.zip : Access a zip file on local filesystem
file:///zipfile.zip/time : Access a folder in a local zip file
dicom://server:104/AETITLE : Access a DICOM server on port 104 with given application entity title.
The plugin architecture is depicted in Fig. 2:
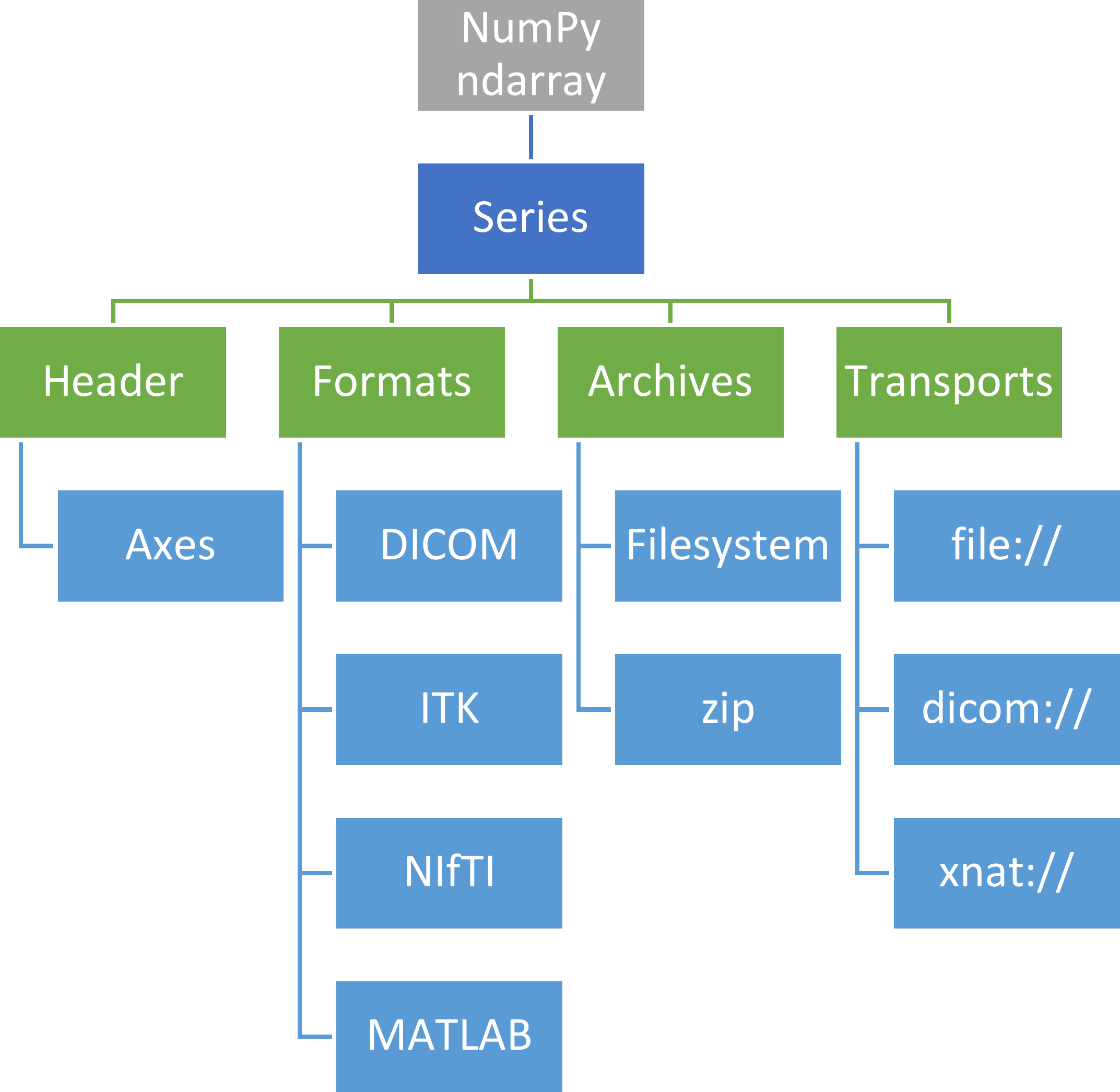
Fig. 2 Plugin Architecture
Series Class
The imagedata.Series class holds an image series (3D or multi-dimensional) loaded
or produced in Python. Figure 1 shows the steps to instantiate an image
series :
>>> from imagedata import Series
>>> si = Series(’dicom/volume/’)
>>> print(si.shape, si.dtype)
(16, 160, 160) uint16
>>> si.spacing
Array([2. , 1.3125, 1.3125])
>>> si.sliceLocations
array([ -3.16799537, -1.16799537, 0.83200463, 2.83200463,
4.83200463, 6.83200463, 8.83200463, 10.83200463,
12.83200463, 14.83200463, 16.83200463, 18.83200463,
20.83200463, 22.83200463, 24.83200463, 26.83200463])
>>> # Save series in output/ directory, original format
>>> si.input_format
’dicom’
>>> si.write(’output/’)
>>> # Save series in ITK format (MHA format by default)
>>> si.write(’itk_output/’, formats=[’itk’])
The addressing of the Series array is row-major (also known as C order), which leads to the most efficient NumPy processing. E.g. (slice, row, column) in the 3D case, and (tag, slice, row, column) in the 4D case. This is contrary to e.g. MATLAB (The MathWorks, Inc.) which addresses arrays in column-major (Fortran) order. Also note that NumPy indices start at zero, while MATLAB indices start at one.
The tag index for a 4D series indicates any attribute that distinguishes the 3D volumes, like time for a dynamic scan, b value for a diffusion weighted scan, flip angle or echo time for contrast weighted scans.
In a pipeline where non-DICOM data are converted to DICOM data, a DICOM template is required to fill in missing attribute values. The original input DICOM images can usually be applied as template, such that a PACS will add the new images as a new series to an existing patient and study. Figure 1 shows an example where the loaded DICOM data are written to files in both original (DICOM) and ITK’s MetaImage formats.
Like the ndarray, the Series object can be sliced. The imagedata package attempts to maintain the geometry of the sliced data. The example in Figure 2 extracts slice 5, showing that the sliceLocations attribute has been adjusted. Next, slice 5 is stored to disk:
>>> # Extract _slice no. 5
>>> slice5 = si[5,…]
>>> slice5.sliceLocations
array(6.8320046343748)
>>> # Save _slice 5 to slice5/ directory
>>> slice5.write(’slice5/’)